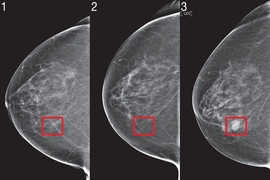
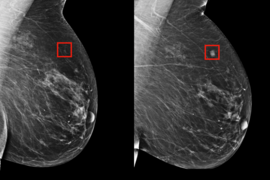
While mammograms are currently the gold standard in breast cancer screening, swirls of controversy exist regarding when and how often they should be administered. On the one hand, advocates argue for the ability to save lives: Women aged 60-69 who receive mammograms, for example, have a 33 percent lower risk of dying compared to those who don’t get mammograms. Meanwhile, others argue about costly and potentially traumatic false positives: A meta-analysis of three randomized trials found a 19 percent over-diagnosis rate from mammography.
Even with some saved lives, and some overtreatment and overscreening, current guidelines are still a catch-all: Women aged 45 to 54 should get mammograms every year. While personalized screening has long been thought of as the answer, tools that can leverage the troves of data to do this lag behind.
This led scientists from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and Jameel Clinic for Machine Learning and Health to ask: Can we use machine learning to provide personalized screening?
Out of this came Tempo, a technology for creating risk-based screening guidelines. Using an AI-based risk model that looks at who was screened and when they got diagnosed, Tempo will recommend a patient return for a mammogram at a specific time point in the future, like six months or three years. The same Tempo policy can be easily adapted to a wide range of possible screening preferences, which would let clinicians pick their desired early-detection-to-screening-cost trade-off, without training new policies.
The model was trained on a large screening mammography dataset from Massachusetts General Hospital (MGH), and was tested on held-out patients from MGH as well as external datasets from Emory, Karolinska Sweden, and Chang Gung Memorial hospitals. Using the team’s previously developed risk-assessment algorithm Mirai, Tempo obtained better early detection than annual screening while requiring 25 percent fewer mammograms overall at Karolinska. At MGH, it recommended roughly a mammogram a year, and obtained a simulated early detection benefit of roughly four-and-a-half months better.
“By tailoring the screening to the patient's individual risk, we can improve patient outcomes, reduce overtreatment, and eliminate health disparities,” says Adam Yala, a PhD student in electrical engineering and computer science, MIT CSAIL affiliate, and lead researcher on a paper describing Tempo published Jan. 13 in Nature Medicine. “Given the massive scale of breast cancer screening, with tens of millions of women getting mammograms every year, improvements to our guidelines are immensely important.”
Early uses of AI in medicine stem back to the 1960s, where many refer to the Dendral experiments as kicking off the field. Researchers created a software system that was considered the first expert kind that automated the decision-making and problem-solving behavior of organic chemists. Sixty years later, deep medicine has greatly evolved drug diagnostics, predictive medicine, and patient care.
“Current guidelines divide the population into a few large groups, like younger or older than 55, and recommend the same screening frequency to all the members of a cohort. The development of AI-based risk models that operate over raw patient data give us an opportunity to transform screening, giving more frequent screens to those who need it and sparing the rest,” says Yala. “A key aspect of these models is that their predictions can evolve over time as a patient’s raw data changes, suggesting that screening policies need to be attuned to changes in risk and be optimized over long periods of patient data.”
Tempo uses reinforcement learning, a machine learning method widely known for success in games like Chess and Go, to develop a “policy” that predicts a followup recommendation for each patient.
The training data here only had information about a patient’s risk at the time points when their mammogram was taken (when they were 50, or 55, for example). The team needed the risk assessment at intermediate points, so they designed their algorithm to learn a patient’s risk at unobserved time points from their observed screenings, which evolved as new mammograms of the patient became available.
The team first trained a neural network to predict future risk assessments given previous ones. This model then estimates patient risk at unobserved time points, and it enables simulation of the risk-based screening policies. Next, they trained that policy, (also a neural network), to maximize the reward (for example, the combination of early detection and screening cost) to the retrospective training set. Eventually, you’d get a recommendation for when to return for the next screen, ranging from six months to three years in the future, in multiples of six months — the standard is only one or two years.
Let’s say Patient A comes in for their first mammogram, and eventually gets diagnosed at Year Four. In Year Two, there’s nothing, so they don’t come back for another two years, but then at Year Four they get a diagnosis. Now there's been two years of gap between the last screen, where a tumor could have grown.
Using Tempo, at that first mammogram, Year Zero, the recommendation might have been to come back in two years. And then at Year Two, it might have seen that risk is high, and recommended that the patient come back in six months, and in the best case, it would be detectable. The model is dynamically changing the patient’s screening frequency, based on how the risk profile is changing.
Tempo uses a simple metric for early detection, which assumes that cancer can be caught up to 18 months in advance. While Tempo outperformed current guidelines across different settings of this assumption (six months, 12 months), none of these assumptions are perfect, as the early detection potential of a tumor depends on that tumor's characteristics. The team suggested that follow-up work using tumor growth models could address this issue.
Also, the screening-cost metric, which counts the total screening volume recommended by Tempo, doesn't provide a full analysis of the entire future cost because it does not explicitly quantify false positive risks or additional screening harms.
There are many future directions that can further improve personalized screening algorithms. The team says one avenue would be to build on the metrics used to estimate early detection and screening costs from retrospective data, which would result in more refined guidelines. Tempo could also be adapted to include different types of screening recommendations, such as leveraging MRI or mammograms, and future work could separately model the costs and benefits of each. With better screening policies, recalculating the earliest and latest age that screening is still cost-effective for a patient might be feasible.
“Our framework is flexible and can be readily utilized for other diseases, other forms of risk models, and other definitions of early detection benefit or screening cost. We expect the utility of Tempo to continue to improve as risk models and outcome metrics are further refined. We're excited to work with hospital partners to prospectively study this technology and help us further improve personalized cancer screening,” says Yala.
Yala wrote the paper on Tempo alongside MIT PhD student Peter G. Mikhael, Fredrik Strand of Karolinska University Hospital, Gigin Lin of Chang Gung Memorial Hospital, Yung-Liang Wan of Chang Gung University, Siddharth Satuluru of Emory University, Thomas Kim of Georgia Tech, Hari Trivedi of Emory University, Imon Banerjee of the Mayo Clinic, Judy Gichoya of the Emory University School of Medicine, Kevin Hughes of MGH, Constance Lehman of MGH, and senior author and MIT Professor Regina Barzilay.
The research is supported by grants from Susan G. Komen, Breast Cancer Research Foundation, Quanta Computing, an Anonymous Foundation, the MIT Jameel-Clinic, Chang Gung Medical Foundation Grant, and by Stockholm Läns Landsting HMT Grant.