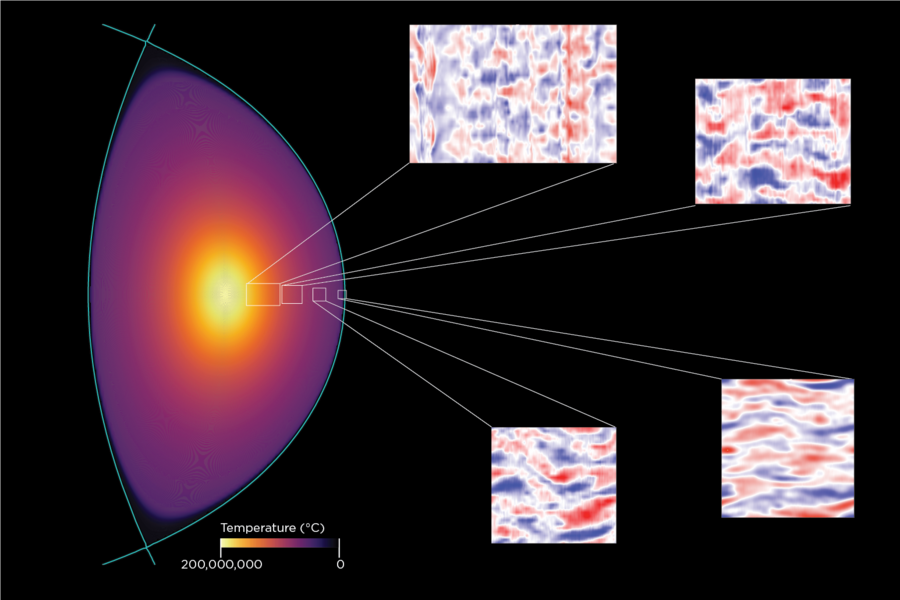
MIT research scientists Pablo Rodriguez-Fernandez and Nathan Howard have just completed one of the most demanding calculations in fusion science — predicting the temperature and density profiles of a magnetically confined plasma via first-principles simulation of plasma turbulence. Solving this problem by brute force is beyond the capabilities of even the most advanced supercomputers. Instead, the researchers used an optimization methodology developed for machine learning to dramatically reduce the CPU time required while maintaining the accuracy of the solution.
Fusion energy
Fusion offers the promise of unlimited, carbon-free energy through the same physical process that powers the sun and the stars. It requires heating the fuel to temperatures above 100 million degrees, well above the point where the electrons are stripped from their atoms, creating a form of matter called plasma. On Earth, researchers use strong magnetic fields to isolate and insulate the hot plasma from ordinary matter. The stronger the magnetic field, the better the quality of the insulation that it provides.
Rodriguez-Fernandez and Howard have focused on predicting the performance expected in the SPARC device, a compact, high-magnetic-field fusion experiment, currently under construction by the MIT spin-out company Commonwealth Fusion Systems (CFS) and researchers from MIT’s Plasma Science and Fusion Center. While the calculation required an extraordinary amount of computer time, over 8 million CPU-hours, what was remarkable was not how much time was used, but how little, given the daunting computational challenge.
The computational challenge of fusion energy
Turbulence, which is the mechanism for most of the heat loss in a confined plasma, is one of the science’s grand challenges and the greatest problem remaining in classical physics. The equations that govern fusion plasmas are well known, but analytic solutions are not possible in the regimes of interest, where nonlinearities are important and solutions encompass an enormous range of spatial and temporal scales. Scientists resort to solving the equations by numerical simulation on computers. It is no accident that fusion researchers have been pioneers in computational physics for the last 50 years.
One of the fundamental problems for researchers is reliably predicting plasma temperature and density given only the magnetic field configuration and the externally applied input power. In confinement devices like SPARC, the external power and the heat input from the fusion process are lost through turbulence in the plasma. The turbulence itself is driven by the difference in the extremely high temperature of the plasma core and the relatively cool temperatures of the plasma edge (merely a few million degrees). Predicting the performance of a self-heated fusion plasma therefore requires a calculation of the power balance between the fusion power input and the losses due to turbulence.
These calculations generally start by assuming plasma temperature and density profiles at a particular location, then computing the heat transported locally by turbulence. However, a useful prediction requires a self-consistent calculation of the profiles across the entire plasma, which includes both the heat input and turbulent losses. Directly solving this problem is beyond the capabilities of any existing computer, so researchers have developed an approach that stitches the profiles together from a series of demanding but tractable local calculations. This method works, but since the heat and particle fluxes depend on multiple parameters, the calculations can be very slow to converge.
However, techniques emerging from the field of machine learning are well suited to optimize just such a calculation. Starting with a set of computationally intensive local calculations run with the full-physics, first-principles CGYRO code (provided by a team from General Atomics led by Jeff Candy) Rodriguez-Fernandez and Howard fit a surrogate mathematical model, which was used to explore and optimize a search within the parameter space. The results of the optimization were compared to the exact calculations at each optimum point, and the system was iterated to a desired level of accuracy. The researchers estimate that the technique reduced the number of runs of the CGYRO code by a factor of four.
New approach increases confidence in predictions
This work, described in a recent publication in the journal Nuclear Fusion, is the highest fidelity calculation ever made of the core of a fusion plasma. It refines and confirms predictions made with less demanding models. Professor Jonathan Citrin, of the Eindhoven University of Technology and leader of the fusion modeling group for DIFFER, the Dutch Institute for Fundamental Energy Research, commented: "The work significantly accelerates our capabilities in more routinely performing ultra-high-fidelity tokamak scenario prediction. This algorithm can help provide the ultimate validation test of machine design or scenario optimization carried out with faster, more reduced modeling, greatly increasing our confidence in the outcomes."
In addition to increasing confidence in the fusion performance of the SPARC experiment, this technique provides a roadmap to check and calibrate reduced physics models, which run with a small fraction of the computational power. Such models, cross-checked against the results generated from turbulence simulations, will provide a reliable prediction before each SPARC discharge, helping to guide experimental campaigns and improving the scientific exploitation of the device. It can also be used to tweak and improve even simple data-driven models, which run extremely quickly, allowing researchers to sift through enormous parameter ranges to narrow down possible experiments or possible future machines.
The research was funded by CFS, with computational support from the National Energy Research Scientific Computing Center, a U.S. Department of Energy Office of Science User Facility.