
Much of the human genome is made of regulatory regions that control which genes are expressed at a given time within a cell. Those regulatory elements can be located near a target gene or up to 2 million base pairs away from the target.
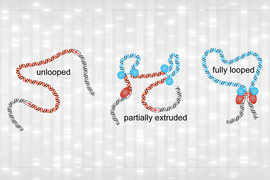
To enable those interactions, the genome loops itself in a 3D structure that brings distant regions close together. Using a new technique, MIT researchers have shown that they can map these interactions with 100 times higher resolution than has previously been possible.
“Using this method, we generate the highest-resolution maps of the 3D genome that have ever been generated, and what we see are a lot of interactions between enhancers and promoters that haven't been seen previously,” says Anders Sejr Hansen, the Underwood-Prescott Career Development Assistant Professor of Biological Engineering at MIT and the senior author of the study. “We are excited to be able to reveal a new layer of 3D structure with our high resolution.”
The researchers’ findings suggest that many genes interact with dozens of different regulatory elements, although further study is needed to determine which of those interactions are the most important to the regulation of a given gene.
“Researchers can now affordably study the interactions between genes and their regulators, which opens a world of possibilities not just for us but also for dozens of labs that have already expressed interest in our method,” says Viraat Goel, an MIT graduate student and one of the lead authors of the paper. “We’re excited to bring the research community a tool that helps them disentangle the mechanisms driving gene regulation.”
MIT postdoc Miles Huseyin is also a lead author of the paper, which appears today in Nature Genetics.
High-resolution mapping
Scientists estimate that more than half of the genome consists of regulatory elements that control genes, which make up only about 2 percent of the genome. Genome-wide association studies, which link genetic variants with specific diseases, have identified many variants that appear in these regulatory regions. Determining which genes these regulatory elements interact with could help researchers understand how those diseases arise and, potentially, how to treat them.
Discovering those interactions requires mapping which parts of the genome interact with each other when chromosomes are packed into the nucleus. Chromosomes are organized into structural units called nucleosomes — strands of DNA tightly wound around proteins — helping the chromosomes fit within the small confines of the nucleus.

Over a decade ago, a team that included researchers from MIT developed a method called Hi-C, which revealed that the genome is organized as a “fractal globule,” which allows the cell to tightly pack its DNA while avoiding knots. This architecture also allows the DNA to easily unfold and refold when needed.
To perform Hi-C, researchers use restriction enzymes to chop the genome into many small pieces and biochemically link pieces that are near each other in 3D space within the cell’s nucleus. They then determine the identities of the interacting pieces by amplifying and sequencing them.
While Hi-C reveals a great deal about the overall 3D organization of the genome, it has limited resolution to pick out specific interactions between genes and regulatory elements such as enhancers. Enhancers are short sequences of DNA that can help to activate the transcription of a gene by binding to the gene’s promoter — the site where transcription begins.
To achieve the resolution necessary to find these interactions, the MIT team built on a more recent technology called Micro-C, which was invented by researchers at the University of Massachusetts Medical School, led by Stanley Hsieh and Oliver Rando. Micro-C was first applied in budding yeast in 2015 and subsequently applied to mammalian cells in three papers in 2019 and 2020 by researchers including Hansen, Hsieh, Rando and others at University of California at Berkeley and at UMass Medical School.
Micro-C achieves higher resolution than Hi-C by using an enzyme known as micrococcal nuclease to chop up the genome. Hi-C’s restriction enzymes cut the genome only at specific DNA sequences that are randomly distributed, resulting in DNA fragments of varying and larger sizes. By contrast, micrococcal nuclease uniformly cuts the genome into nucleosome-sized fragments, each of which contains 150 to 200 DNA base pairs. This uniformity of small fragments grants Micro-C its superior resolution over Hi-C.
However, since Micro-C surveys the entire genome, this approach still doesn’t achieve high enough resolution to identify the types of interactions the researchers wanted to see. For example, if you want to look at how 100 different genome sites interact with each other, you need to sequence at least 100 multiplied by 100 times, or 10,000. The human genome is very large and contains around 22 million sites at nucleosome resolution. Therefore, Micro-C mapping of the entire human genome would require at least 22 million multiplied by 22 million sequencing reads, costing more than $1 billion.
To bring that cost down, the team devised a way to perform a more targeted sequencing of the genome’s interactions, allowing them to focus on segments of the genome that contain genes of interest. By focusing on regions spanning a few million base pairs, the number of possible genomic sites decreases a thousandfold and the sequencing costs decrease a millionfold, down to about $1,000. The new method, called Region Capture Micro-C (RCMC), is therefore able to inexpensively generate maps 100 times richer in information than other published techniques for a fraction of the cost.
“Now we have a method for getting ultra-high-resolution 3D genome structure maps in a very affordable manner. Previously, it was so inaccessible financially because you would need millions, if not billions of dollars, to get high resolution,” Hansen says. “The one limitation is that you can't get the whole genome, so you need to know approximately what region you're interested in, but you can get very high resolution, very affordably.”
Many interactions
In this study, the researchers focused on five regions varying in size from hundreds of thousands to about 2 million base pairs, which they chose due to interesting features revealed by previous studies. Those include a well-characterized gene called Sox2, which plays a key role in tissue formation during embryonic development.
After capturing and sequencing the DNA segments of interest, the researchers found many enhancers that interact with Sox2, as well as interactions between nearby genes and enhancers that were previously unseen. In other regions, especially those full of genes and enhancers, some genes interacted with as many as 50 other DNA segments, and on average each interacting site contacted about 25 others.
“People have seen multiple interactions from one bit of DNA before, but it's usually on the order of two or three, so seeing this many of them was quite significant in terms of difference,” Huseyin says.
However, the researchers’ technique doesn’t reveal whether all of those interactions occur simultaneously or at different times, or which of those interactions are the most important.
The researchers also found that DNA appears to coil itself into nested “microcompartments” that facilitate these interactions, but they weren’t able to determine how microcompartments form. The researchers hope that further study into the underlying mechanisms could shed light on the fundamental question of how genes are regulated.
“Even though we're not currently aware of what may be causing these microcompartments, and we have all these open questions in front of us, we at least have a tool to really stringently ask those questions,” Goel says.
In addition to pursuing those questions, the MIT team also plans to work with researchers at Boston Children’s Hospital to apply this type of analysis to genomic regions that have been linked with blood disorders in genome-wide association studies. They are also collaborating with researchers at Harvard Medical School to study variants linked to metabolic disorders.
Christine Eyler, a medical instructor at Duke University School of Medicine, says the new technique will provide a valuable tool for analyzing ultrafine chromatin looping architecture.
“I anticipate that pairing the ultraresolved RCMC contact looping data with other assays that define specific regulatory elements will reveal important new insights as to the relationship between nuclear structure and gene regulatory function,” says Eyler, who was not involved in this study. “Having performed the assay in our own group, we were impressed by the fact that the protocol is easy to follow as written (even for scientists not previously experienced in topology assays), and is economically very efficient given the wealth of information that it provides.”
The research was funded by the Koch Institute Support (core) Grant from the National Cancer Institute, the National Institutes of Health, the National Science Foundation, a Solomon Buchsbaum Research Support Committee Award, the Koch Institute Frontier Research Fund, an NIH Fellowship and an EMBO Fellowship.