From the "Mona Lisa" to the "Girl with a Pearl Earring," some images linger in the mind long after others have faded. Ask an artist why, and you might hear some generally-accepted principles for making memorable art. Now there’s an easier way to learn: ask an artificial intelligence model to draw an example.
A new study using machine learning to generate images ranging from a memorable cheeseburger to a forgettable cup of coffee shows in close detail what makes a portrait or scene stand out. The images that human subjects in the study remembered best featured bright colors, simple backgrounds, and subjects that were centered prominently in the frame. Results were presented this week at the International Conference on Computer Vision.
“A picture is worth a thousand words,” says the study’s co-senior author Phillip Isola, the Bonnie and Marty (1964) Tenenbaum CD Assistant Professor of Electrical Engineering and Computer Science at MIT. “A lot has been written about memorability, but this method lets us actually visualize what memorability looks like. It gives us a visual definition for something that’s hard to put into words."
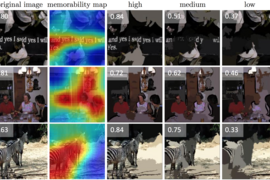
The work builds on an earlier model, MemNet, which rates the memorability of an image and highlights the features in the picture influencing its decision. MemNet’s predictions are based on the results of an online study in which 60,000 images were shown to human subjects and ranked by how easily they were remembered.
The model in the current study, GANalyze, uses a machine learning technique called generative adversarial networks, or GANs, to visualize a single image as it inches its way from "meh" to memorable. GANalyze lets viewers visualize the incremental transformation of, say, a blurry panda lost in the bamboo into a panda that dominates the frame, its black eyes, ears, and paws contrasting sharply and adorably with its white mug.
The image-riffing GAN has three modules. An assessor, based on MemNet, turns the memorability knob on a target image and calculates how to achieve the desired effect. A transformer executes its instructions, and a generator outputs the final image.
The progression has the dramatic feel of a time-lapse image. A cheeseburger shifted to the far end of the memorability scale looks fatter, brighter, and, as the authors note, “tastier,” than its earlier incarnations. A ladybug looks shinier and more purposeful. In an unexpected twist, a pepper on the vine turns chameleon-like from green to red.
The researchers also looked at which features influence memorability most. In online experiments, human subjects were shown images of varying memorability and asked to flag any repeats. The duplicates that were stickiest, it turns out, featured subjects closer up, making animals or objects in the frame appear larger. The next most important factors were brightness, having the subject centered in the frame, and in a square or circular shape.
“The human brain evolved to focus most on these features, and that’s what the GAN picks up on,” says study co-author Lore Goetschalckx, a visiting graduate student from Katholieke Universiteit Leuven in Belgium.
The researchers also reconfigured GANanalyze to generate images of varying aesthetic and emotional appeal. They found that images rated higher on aesthetic and emotional grounds were brighter, more colorful, and had a shallow depth of field that blurred the background, much like the most memorable pictures. However, the most aesthetic images were not always memorable.
GANalyze has a number of potential applications, the researchers say. It could be used to detect, and even treat, memory loss by enhancing objects in an augmented reality system.
“Instead of using a drug to enhance memory, you might enhance the world through an augmented-reality device to make easily misplaced items like keys stand out,” says study co-senior author Aude Oliva, a principal research scientist at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and executive director of the MIT Quest for Intelligence.
GANalyze could also be used to create unforgettable graphics to help readers retain information. “It could revolutionize education,” says Oliva. Finally, GANs are already starting to be used to generate synthetic, realistic images of the world to help train automated systems to recognize places and objects they are unlikely to encounter in real life.
Generative models offer new, creative ways for humans and machines to collaborate. Study co-author Alex Andonian, a graduate student at MIT’s Department of Electrical Engineering and Computer Science, says that's why he has chosen to make them the focus of his PhD.
“Design software lets you adjust the brightness of an image, but not its overall memorability or aesthetic appeal — GANs let you do that,” he says. “We’re just starting to scratch the surface of what these models can do.”
The study was funded by the U.S. National Science Foundation.