
The sentient Magic Carpet from “Aladdin” might have a new competitor. While it can’t fly or speak, a new tactile sensing carpet from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) can estimate human poses without using cameras, in a step toward improving self-powered personalized health care, smart homes, and gaming.
Many of our daily activities involve physical contact with the ground: walking, exercising, or resting. These embedded interactions contain a wealth of information that help us better understand people’s movements.
Previous research has leveraged use of single RGB cameras, (think Microsoft Kinect), wearable omnidirectional cameras, and even plain old off-the-shelf webcams, but with the inevitable byproducts of camera occlusions and privacy concerns.
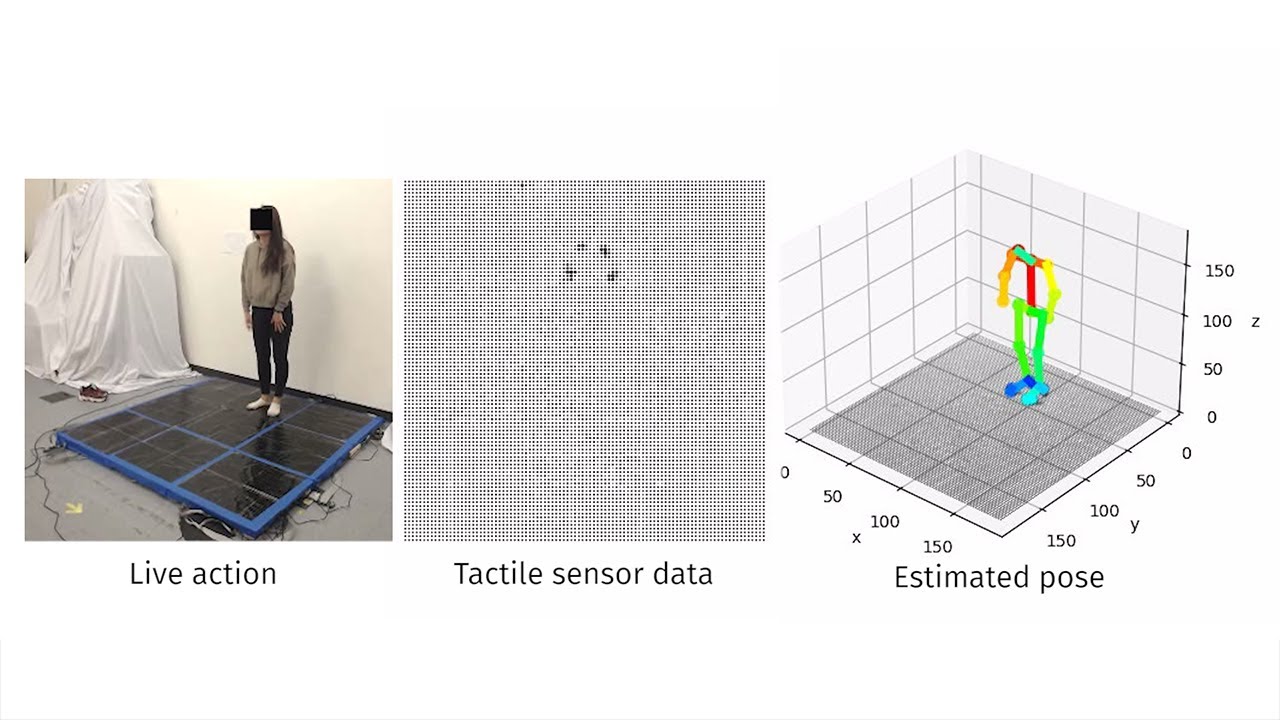
The CSAIL team’s system only used cameras to create the dataset the system was trained on, and only captured the moment of the person performing the activity. To infer the 3D pose, a person would simply have to get on the carpet, perform an action, and then the team’s deep neural network, using just the tactile information, could determine if the person was doing situps, stretching, or doing another action.
“You can imagine leveraging this model to enable a seamless health-monitoring system for high-risk individuals, for fall detection, rehab monitoring, mobility, and more,” says Yiyue Luo, a lead author on a paper about the carpet.
The carpet itself, which is low-cost and scalable, was made of commercial, pressure-sensitive film and conductive thread, with over 9,000 sensors spanning 36-by-2 feet. (Most living room rug sizes are 8-by-10 and 9-by-12.)
Each of the sensors on the carpet converts the human’s pressure into an electrical signal, through the physical contact between people’s feet, limbs, torso, and the carpet. The system was specifically trained on synchronized tactile and visual data, such as a video and corresponding heat map of someone doing a pushup.
The model takes the pose extracted from the visual data as the ground truth, uses the tactile data as input, and finally outputs the 3D human pose.
This might look something like when, after stepping onto the carpet and doing a set up of pushups, the system is able to produce an image or video of someone doing a pushup.
In fact, the model was able to predict a person’s pose with an error margin (measured by the distance between predicted human body key points and ground truth key points) by less than 10 centimeters. For classifying specific actions, the system was accurate 97 percent of the time.
“You could envision using the carpet for workout purposes. Based solely on tactile information, it can recognize the activity, count the number of reps, and calculate the amount of burned calories,” says MIT CSAIL PhD student Yunzhu Li, a co-author on the paper.
Since much of the pressure distributions were prompted by movement of the lower body and torso, that information was more accurate than the upper-body data. Also, the model was unable to predict poses without more explicit floor contact, like free-floating legs during situps, or a twisted torso while standing up.
While the system can understand a single person, the scientists, down the line, want to improve the metrics for multiple users, where two people might be dancing or hugging on the carpet. They also hope to gain more information from the tactical signals, such as a person’s height or weight.
Luo wrote the paper alongside Li and MIT CSAIL PhD student Yunzhu Pratyusha Sharma, MIT CSAIL mechanical engineer Michael Foshey, MIT CSAIL postdoc Wan Shou, and MIT professors Tomas Palacios, Antonio Torralba, and Wojciech Matusik. The work is funded by the Toyota Research Institute.







