The inner child in many of us feels an overwhelming sense of joy when stumbling across a pile of the fluorescent, rubbery mixture of water, salt, and flour that put goo on the map: play dough. (Even if this happens rarely in adulthood.)
While manipulating play dough is fun and easy for 2-year-olds, the shapeless sludge is hard for robots to handle. Machines have become increasingly reliable with rigid objects, but manipulating soft, deformable objects comes with a laundry list of technical challenges, and most importantly, as with most flexible structures, if you move one part, you’re likely affecting everything else.
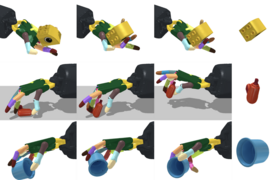
Scientists from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and Stanford University recently let robots take their hand at playing with the modeling compound, but not for nostalgia’s sake. Their new system learns directly from visual inputs to let a robot with a two-fingered gripper see, simulate, and shape doughy objects. “RoboCraft” could reliably plan a robot’s behavior to pinch and release play dough to make various letters, including ones it had never seen. With just 10 minutes of data, the two-finger gripper rivaled human counterparts that teleoperated the machine — performing on-par, and at times even better, on the tested tasks.
“Modeling and manipulating objects with high degrees of freedom are essential capabilities for robots to learn how to enable complex industrial and household interaction tasks, like stuffing dumplings, rolling sushi, and making pottery,” says Yunzhu Li, CSAIL PhD student and author on a new paper about RoboCraft. “While there’s been recent advances in manipulating clothes and ropes, we found that objects with high plasticity, like dough or plasticine — despite ubiquity in those household and industrial settings — was a largely underexplored territory. With RoboCraft, we learn the dynamics models directly from high-dimensional sensory data, which offers a promising data-driven avenue for us to perform effective planning.”

With undefined, smooth material, the whole structure needs to be accounted for before you can do any type of efficient and effective modeling and planning. By turning the images into graphs of little particles, coupled with algorithms, RoboCraft, using a graph neural network as the dynamics model, makes more accurate predictions about the material's change of shapes.
Typically, researchers have used complex physics simulators to model and understand force and dynamics being applied to objects, but RoboCraft simply uses visual data. The inner-workings of the system relies on three parts to shape soft material into, say, an “R.”
The first part — perception — is all about learning to “see.” It uses cameras to collect raw, visual sensor data from the environment, which are then turned into little clouds of particles to represent the shapes. A graph-based neural network then uses said particle data to learn to “simulate” the object’s dynamics, or how it moves. Then, algorithms help plan the robot’s behavior so it learns to “shape” a blob of dough, armed with the training data from the many pinches. While the letters are a bit loose, they’re indubitably representative.
Besides cutesy shapes, the team is (actually) working on making dumplings from dough and a prepared filling. Right now, with just a two finger gripper, it’s a big ask. RoboCraft would need additional tools (a baker needs multiple tools to cook; so do robots) — a rolling pin, a stamp, and a mold.
A more far in the future domain the scientists envision is using RoboCraft for assistance with household tasks and chores, which could be of particular help to the elderly or those with limited mobility. To accomplish this, given the many obstructions that could take place, a much more adaptive representation of the dough or item would be needed, and as well as exploration into what class of models might be suitable to capture the underlying structural systems.
“RoboCraft essentially demonstrates that this predictive model can be learned in very data-efficient ways to plan motion. In the long run, we are thinking about using various tools to manipulate materials,” says Li. “If you think about dumpling or dough making, just one gripper wouldn’t be able to solve it. Helping the model understand and accomplish longer-horizon planning tasks, such as, how the dough will deform given the current tool, movements and actions, is a next step for future work.”
Li wrote the paper alongside Haochen Shi, Stanford master’s student; Huazhe Xu, Stanford postdoc; Zhiao Huang, PhD student at the University of California at San Diego; and Jiajun Wu, assistant professor at Stanford. They will present the research at the Robotics: Science and Systems conference in New York City. The work is in part supported by the Stanford Institute for Human-Centered AI (HAI), the Samsung Global Research Outreach (GRO) Program, the Toyota Research Institute (TRI), and Amazon, Autodesk, Salesforce, and Bosch.