The proliferation of big data across domains, from banking to health care to environmental monitoring, has spurred increasing demand for machine learning tools that help organizations make decisions based on the data they gather.
That growing industry demand has driven researchers to explore the possibilities of automated machine learning (AutoML), which seeks to automate the development of machine learning solutions in order to make them accessible for nonexperts, improve their efficiency, and accelerate machine learning research. For example, an AutoML system might enable doctors to use their expertise interpreting electroencephalography (EEG) results to build a model that can predict which patients are at higher risk for epilepsy — without requiring the doctors to have a background in data science.
Yet, despite more than a decade of work, researchers have been unable to fully automate all steps in the machine learning development process. Even the most efficient commercial AutoML systems still require a prolonged back-and-forth between a domain expert, like a marketing manager or mechanical engineer, and a data scientist, making the process inefficient.
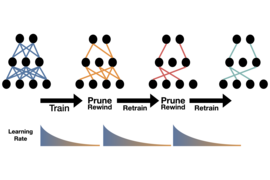
Kalyan Veeramachaneni, a principal research scientist in the MIT Laboratory for Information and Decision Systems who has been studying AutoML since 2010, has co-authored a paper in the journal ACM Computing Surveys that details a seven-tiered schematic to evaluate AutoML tools based on their level of autonomy.
A system at level zero has no automation and requires a data scientist to start from scratch and build models by hand, while a tool at level six is completely automated and can be easily and effectively used by a nonexpert. Most commercial systems fall somewhere in the middle.
Veeramachaneni spoke with MIT News about the current state of AutoML, the hurdles that prevent truly automatic machine learning systems, and the road ahead for AutoML researchers.
Q: How has automatic machine learning evolved over the past decade, and what is the current state of AutoML systems?
A: In 2010, we started to see a shift, with enterprises wanting to invest in getting value out of their data beyond just business intelligence. So then came the question, maybe there are certain things in the development of machine learning-based solutions that we can automate? The first iteration of AutoML was to make our own jobs as data scientists more efficient. Can we take away the grunt work that we do on a day-to-day basis and automate that by using a software system? That area of research ran its course until about 2015, when we realized we still weren’t able to speed up this development process.
Then another thread emerged. There are a lot of problems that could be solved with data, and they come from experts who know those problems, who live with them on a daily basis. These individuals have very little to do with machine learning or software engineering. How do we bring them into the fold? That is really the next frontier.
There are three areas where these domain experts have strong input in a machine learning system. The first is defining the problem itself and then helping to formulate it as a prediction task to be solved by a machine learning model. Second, they know how the data have been collected, so they also know intuitively how to process that data. And then third, at the end, machine learning models only give you a very tiny part of a solution — they just give you a prediction. The output of a machine learning model is just one input to help a domain expert get to a decision or action.
Q: What steps of the machine learning pipeline are the most difficult to automate, and why has automating them been so challenging?
A: The problem-formulation part is extremely difficult to automate. For example, if I am a researcher who wants to get more government funding, and I have a lot of data about the content of the research proposals that I write and whether or not I receive funding, can machine learning help there? We don’t know yet. In problem formulation, I use my domain expertise to translate the problem into something that is more tangible to predict, and that requires somebody who knows the domain very well. And he or she also knows how to use that information post-prediction. That problem is refusing to be automated.
There is one part of problem-formulation that could be automated. It turns out that we can look at the data and mathematically express several possible prediction tasks automatically. Then we can share those prediction tasks with the domain expert to see if any of them would help in the larger problem they are trying to tackle. Then once you pick the prediction task, there are a lot of intermediate steps you do, including feature engineering, modeling, etc., that are very mechanical steps and easy to automate.
But defining the prediction tasks has typically been a collaborative effort between data scientists and domain experts because, unless you know the domain, you can’t translate the domain problem into a prediction task. And then sometimes domain experts don’t know what is meant by “prediction.” That leads to the major, significant back and forth in the process. If you automate that step, then machine learning penetration and the use of data to create meaningful predictions will increase tremendously.
Then what happens after the machine learning model gives a prediction? We can automate the software and technology part of it, but at the end of the day, it is root cause analysis and human intuition and decision making. We can augment them with a lot of tools, but we can’t fully automate that.
Q: What do you hope to achieve with the seven-tiered framework for evaluating AutoML systems that you outlined in your paper?
A: My hope is that people start to recognize that some levels of automation have already been achieved and some still need to be tackled. In the research community, we tend to focus on what we are comfortable with. We have gotten used to automating certain steps, and then we just stick to it. Automating these other parts of the machine learning solution development is very important, and that is where the biggest bottlenecks remain.
My second hope is that researchers will very clearly understand what domain expertise means. A lot of this AutoML work is still being conducted by academics, and the problem is that we often don’t do applied work. There is not a crystal-clear definition of what a domain expert is and in itself, “domain expert,” is a very nebulous phrase. What we mean by domain expert is the expert in the problem you are trying to solve with machine learning. And I am hoping that everyone unifies around that because that would make things so much clearer.
I still believe that we are not able to build that many models for that many problems, but even for the ones that we are building, the majority of them are not getting deployed and used in day-to-day life. The output of machine learning is just going to be another data point, an augmented data point, in someone’s decision making. How they make those decisions, based on that input, how that will change their behavior, and how they will adapt their style of working, that is still a big, open question. Once we automate everything, that is what’s next.
We have to determine what has to fundamentally change in the day-to-day workflow of someone giving loans at a bank, or an educator trying to decide whether he or she should change the assignments in an online class. How are they going to use machine learning’s outputs? We need to focus on the fundamental things we have to build out to make machine learning more usable.