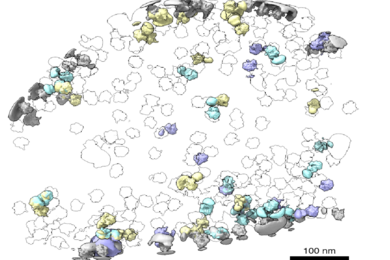
Exploring the cellular neighborhood
Software allows scientists to model shapeshifting proteins in native cellular environments.
Software allows scientists to model shapeshifting proteins in native cellular environments.

MIT spinout DataCebo helps companies bolster their datasets by creating synthetic data that mimic the real thing.

Lightmatter, founded by three MIT alumni, is using photonic computing to reinvent how chips communicate and calculate.

After acquiring data science and AI skills from MIT, Jospin Hassan shared them with his community in the Dzaleka Refugee Camp in Malawi and built pathways for talented learners.

Alumni-founded Pienso has developed a user-friendly AI builder so domain experts can build solutions without writing any code.
An easy-to-use technique could assist everyone from economists to sports analysts.

The graduate students will aim to commercialize innovations in AI, machine learning, and data science.

Exploiting the symmetry within datasets, MIT researchers show, can decrease the amount of data needed for training neural networks.

Hundreds of participants from around the world joined the sixth annual MIT Policy Hackathon to develop data-informed policy solutions to challenges in health, housing, and more.

Collaborative brings together charter school policy, practice, and research communities to help make research on charters more actionable, rigorous, and policy-relevant.

MIT CSAIL researchers develop advanced machine-learning models that outperform current methods in detecting pancreatic ductal adenocarcinoma.

A system designed at MIT could allow sensors to operate in remote settings, without batteries.

MIT’s new chief officer for business and digital transformation describes how the Institute is embarking on an effort to renew its digital landscape.

At an MIT Blueprint Labs Preschool Research Convening, researchers present studies on early childhood education and discuss new research directions with practitioners.

A multimodal system uses models trained on language, vision, and action data to help robots develop and execute plans for household, construction, and manufacturing tasks.