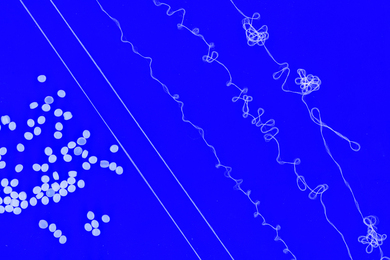
Imagine that you’re traveling to Boston for a weekend conference. You arrive in the city’s South Station transportation center and decide to take the Red Line subway to Kendall Square in Cambridge. Once you locate the subway platform, how much information are you able to glean from a glance at the Massachusetts Bay Transportation Authority (MBTA) posted subway map?
For years, Ruth Rosenholtz, a principal research scientist at the Department of Brain and Cognitive Sciences and the Computer Science and Artificial Intelligence Laboratory (CSAIL) at MIT, has studied how the human visual system, in particular peripheral vision, collects information.
Now Rosenholtz and her research group have developed a computational model of human vision in an effort to understand peripheral visual processing. Beyond providing a greater understanding of how peripheral vision works, Rosenholtz’s computational model can be applied to the design of everything from navigational systems, websites and educational tools to advertisements, in order to predict the usability of a particular display.
When Rosenholtz’s students heard about the MBTA’s map redesign competition — where the public submitted redesigned subway maps and then voted on a winner to be selected as the official new map — they decided to run the redesigned maps through their computational model to see which map looked best peripherally.
“Most people don’t realize how important peripheral vision is for everyday life. Imagine how difficult it would be to read a subway map through a small aperture that prevented you from using your peripheral vision,” Rosenholtz says. “Subway maps are visually complex, and you can’t expect to see everything at a glance. But a viewer should be able to retain some useful information.”
The team initially developed their model of peripheral vision based on their understanding of the perception of simple displays, and then advanced to testing it on the perception of geographical maps.
For any given image, the model developed by Rosenholtz and her team provides a visual representation of the information available in the periphery. For example, it can provide information on whether or not a viewer looking at the center of a street map can easily locate the city’s different public parks, major thoroughfares and landmarks.
In previous work, Rosenholtz’s group performed behavioral experiments in which human subjects were asked to perform visual tasks, such as finding a route on a complicated map using only peripheral vision. The team found that the model’s predictions were consistent with the information human subjects were able to draw from the map.
“If you’re looking at an MBTA map, the model makes predictions about how clearly you can see different subways line and stops,” says Lavanya Sharan, a postdoc associate in Rosenholtz’s group. “We saw an opportunity with the MBTA contest to run our model on the different entries and predict which map might be the most useful.”
The group applied the model based on a user stationed at the Kendall/MIT stop, looking at a large MBTA map, the size of those currently posted in subway stations. By evaluating the different entries, the team found many interesting characteristics that may make a map more useful at a glance.
One of the entries used raised bumps to depict subway stops, which made the stops more noticeable, as opposed to the more commonly used white circles. In all entries, the Silver Line was hard to locate due to its light color; the Green Line branches were easier to comprehend when represented as parallel lines.
Logan Airport, a key location for many travelers in Boston, was difficult to distinguish in all but one entry that prominently highlighted its position. Additionally, the “T” logo, while mostly irrelevant to using the map, was a prominent feature in most entries.
“Our model provides you with a representation of the information that you lose in your periphery when looking at these subway maps. It can show the uncertainty you have about features of the map that you aren’t looking at directly,” says Shaiyan Keshvari, a graduate student in the MIT Department of Brain and Cognitive Sciences.
In the future, the team hopes to improve the model so that it can provide more quantitative information on what the human visual system gathers from images. The group recently received funding to work on understanding the limitations and strengths of Google Glass (a wearable computer with an optical head-mounted display), and how the human visual system can simultaneously process images projected onto Google Glass and the visual input from the real world.
Former members of Rosenholtz’s research group — Benjamin Balas, Alvin Raj and Krista Ehinger — also contributed to this research. For more information on Rosenholtz’s work, please visit: http://persci.mit.edu/people/rosenholtz.
For years, Ruth Rosenholtz, a principal research scientist at the Department of Brain and Cognitive Sciences and the Computer Science and Artificial Intelligence Laboratory (CSAIL) at MIT, has studied how the human visual system, in particular peripheral vision, collects information.
Now Rosenholtz and her research group have developed a computational model of human vision in an effort to understand peripheral visual processing. Beyond providing a greater understanding of how peripheral vision works, Rosenholtz’s computational model can be applied to the design of everything from navigational systems, websites and educational tools to advertisements, in order to predict the usability of a particular display.
When Rosenholtz’s students heard about the MBTA’s map redesign competition — where the public submitted redesigned subway maps and then voted on a winner to be selected as the official new map — they decided to run the redesigned maps through their computational model to see which map looked best peripherally.
“Most people don’t realize how important peripheral vision is for everyday life. Imagine how difficult it would be to read a subway map through a small aperture that prevented you from using your peripheral vision,” Rosenholtz says. “Subway maps are visually complex, and you can’t expect to see everything at a glance. But a viewer should be able to retain some useful information.”
The team initially developed their model of peripheral vision based on their understanding of the perception of simple displays, and then advanced to testing it on the perception of geographical maps.
For any given image, the model developed by Rosenholtz and her team provides a visual representation of the information available in the periphery. For example, it can provide information on whether or not a viewer looking at the center of a street map can easily locate the city’s different public parks, major thoroughfares and landmarks.
In previous work, Rosenholtz’s group performed behavioral experiments in which human subjects were asked to perform visual tasks, such as finding a route on a complicated map using only peripheral vision. The team found that the model’s predictions were consistent with the information human subjects were able to draw from the map.
“If you’re looking at an MBTA map, the model makes predictions about how clearly you can see different subways line and stops,” says Lavanya Sharan, a postdoc associate in Rosenholtz’s group. “We saw an opportunity with the MBTA contest to run our model on the different entries and predict which map might be the most useful.”
The group applied the model based on a user stationed at the Kendall/MIT stop, looking at a large MBTA map, the size of those currently posted in subway stations. By evaluating the different entries, the team found many interesting characteristics that may make a map more useful at a glance.
One of the entries used raised bumps to depict subway stops, which made the stops more noticeable, as opposed to the more commonly used white circles. In all entries, the Silver Line was hard to locate due to its light color; the Green Line branches were easier to comprehend when represented as parallel lines.
Logan Airport, a key location for many travelers in Boston, was difficult to distinguish in all but one entry that prominently highlighted its position. Additionally, the “T” logo, while mostly irrelevant to using the map, was a prominent feature in most entries.
“Our model provides you with a representation of the information that you lose in your periphery when looking at these subway maps. It can show the uncertainty you have about features of the map that you aren’t looking at directly,” says Shaiyan Keshvari, a graduate student in the MIT Department of Brain and Cognitive Sciences.
In the future, the team hopes to improve the model so that it can provide more quantitative information on what the human visual system gathers from images. The group recently received funding to work on understanding the limitations and strengths of Google Glass (a wearable computer with an optical head-mounted display), and how the human visual system can simultaneously process images projected onto Google Glass and the visual input from the real world.
Former members of Rosenholtz’s research group — Benjamin Balas, Alvin Raj and Krista Ehinger — also contributed to this research. For more information on Rosenholtz’s work, please visit: http://persci.mit.edu/people/rosenholtz.