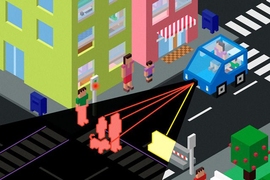
Imagine you’re sitting in the driver’s seat of an autonomous car, cruising along a highway and staring down at your smartphone. Suddenly, the car detects a moose charging out of the woods and alerts you to take the wheel. Once you look back at the road, how much time will you need to safely avoid the collision?
MIT researchers have found an answer in a new study that shows humans need about 390 to 600 milliseconds to detect and react to road hazards, given only a single glance at the road — with younger drivers detecting hazards nearly twice as fast as older drivers. The findings could help developers of autonomous cars ensure they are allowing people enough time to safely take the controls and steer clear of unexpected hazards.
Previous studies have examined hazard response times while people kept their eyes on the road and actively searched for hazards in videos. In this new study, recently published in the Journal of Experimental Psychology: General, the researchers examined how quickly drivers can recognize a road hazard if they’ve just looked back at the road. That’s a more realistic scenario for the coming age of semiautonomous cars that require human intervention and may unexpectedly hand over control to human drivers when facing an imminent hazard.
“You’re looking away from the road, and when you look back, you have no idea what’s going on around you at first glance,” says lead author Benjamin Wolfe, a postdoc in the Computer Science and Artificial Intelligence Laboratory (CSAIL). “We wanted to know how long it takes you to say, ‘A moose is walking into the road over there, and if I don’t do something about it, I’m going to take a moose to the face.’”
For their study, the researchers built a unique dataset that includes YouTube dashcam videos of drivers responding to road hazards — such as objects falling off truck beds, moose running into the road, 18-wheelers toppling over, and sheets of ice flying off car roofs — and other videos without road hazards. Participants were shown split-second snippets of the videos, in between blank screens. In one test, they indicated if they detected hazards in the videos. In another test, they indicated if they would react by turning left or right to avoid a hazard.
The results indicate that younger drivers are quicker at both tasks: Older drivers (55 to 69 years old) required 403 milliseconds to detect hazards in videos, and 605 milliseconds to choose how they would avoid the hazard. Younger drivers (20 to 25 years old) only needed 220 milliseconds to detect and 388 milliseconds to choose.
Those age results are important, Wolfe says. When autonomous vehicles are ready to hit the road, they’ll most likely be expensive. “And who is more likely to buy expensive vehicles? Older drivers,” he says. “If you build an autonomous vehicle system around the presumed capabilities of reaction times of young drivers, that doesn’t reflect the time older drivers need. In that case, you’ve made a system that’s unsafe for older drivers.”
Joining Wolfe on the paper are: Bobbie Seppelt, Bruce Mehler, Bryan Reimer, of the MIT AgeLab, and Ruth Rosenholtz of the Department of Brain and Cognitive Sciences and CSAIL.
Playing “the worst video game ever”
In the study, 49 participants sat in front of a large screen that closely matched the visual angle and viewing distance for a driver, and watched 200 videos from the Road Hazard Stimuli dataset for each test. They were given a toy wheel, brake, and gas pedals to indicate their responses. “Think of it as the worst video game ever,” Wolfe says.
The dataset includes about 500 eight-second dashcam videos of a variety of road conditions and environments. About half of the videos contain events leading to collisions or near collisions. The other half try to closely match each of those driving conditions, but without any hazards. Each video is annotated at two critical points: the frame when a hazard becomes apparent, and the first frame of the driver’s response, such as braking or swerving.
Before each video, participants were shown a split-second white noise mask. When that mask disappeared, participants saw a snippet of a random video that did or did not contain an imminent hazard. After the video, another mask appeared. Directly following that, participants stepped on the brake if they saw a hazard or the gas if they didn’t. There was then another split-second pause on a black screen before the next mask popped up.
When participants started the experiment, the first video they saw was shown for 750 milliseconds. But the duration changed during each test, depending on the participants’ responses. If a participant responded incorrectly to one video, the next video’s duration would extend slightly. If they responded correctly, it would shorten. In the end, durations ranged from a single frame (33 milliseconds) up to one second. “If they got it wrong, we assumed they didn’t have enough information, so we made the next video longer. If they got it right, we assumed they could do with less information, so made it shorter,” Wolfe says.
The second task used the same setup to record how quickly participants could choose a response to a hazard. For that, the researchers used a subset of videos where they knew the response was to turn left or right. The video stops, and the mask appears on the first frame that the driver begins to react. Then, participants turned the wheel either left or right to indicate where they’d steer.
“It’s not enough to say, ‘I know something fell into road in my lane.’ You need to understand that there’s a shoulder to the right and a car in the next lane that I can’t accelerate into, because I’ll have a collision,” Wolfe says.
More time needed
The MIT study didn’t record how long it actually takes people to, say, physically look up from their phones or turn a wheel. Instead, it showed people need up to 600 milliseconds to just detect and react to a hazard, while having no context about the environment.
Wolfe thinks that’s concerning for autonomous vehicles, since they may not give humans adequate time to respond, especially under panic conditions. Other studies, for instance, have found that it takes people who are driving normally, with their eyes on the road, about 1.5 seconds to physically avoid road hazards, starting from initial detection.
Driverless cars will already require a couple hundred milliseconds to alert a driver to a hazard, Wolfe says. “That already bites into the 1.5 seconds,” he says. “If you look up from your phone, it may take an additional few hundred milliseconds to move your eyes and head. That doesn’t even get into time it’ll take to reassert control and brake or steer. Then, it starts to get really worrying.”
Next, the researchers are studying how well peripheral vision helps in detecting hazards. Participants will be asked to stare at a blank part of the screen — indicating where a smartphone may be mounted on a windshield — and similarly pump the brakes when they notice a road hazard.
The work is sponsored, in part, by the Toyota Research Institute.