When we open our eyes in the morning and take in that first scene of the day, we don’t give much thought to the fact that our brain is processing the objects within our field of view with great efficiency and that it is compensating for a lack of information about our surroundings — all in order to allow us to go about our daily functions. The glass of water you left on the nightstand when preparing for bed is now partially blocked from your line of sight by your alarm clock, yet you know that it is a glass.
This seemingly simple ability for humans to recognize partially occluded objects — defined in this situation as the effect of one object in a 3-D space blocking another object from view — has been a complicated problem for the computer vision community. Martin Schrimpf, a graduate student in the DiCarlo lab in the Department of Brain and Cognitive Sciences at MIT, explains that machines have become increasingly adept at recognizing whole items quickly and confidently, but when something covers part of that item from view, this task becomes increasingly difficult for the models to accurately recognize the article.
“For models from computer vision to function in everyday life, they need to be able to digest occluded objects just as well as whole ones — after all, when you look around, most objects are partially hidden behind another object,” says Schrimpf, co-author of a paper on the subject that was recently published in the Proceedings of the National Academy of Sciences (PNAS).
In the new study, he says, “we dug into the underlying computations in the brain and then used our findings to build computational models. By recapitulating visual processing in the human brain, we are thus hoping to also improve models in computer vision.”
How are we as humans able to repeatedly do this everyday task without putting much thought and energy into this action, identifying whole scenes quickly and accurately after injesting just pieces? Researchers in the study started with the human visual cortex as a model for how to improve the performance of machines in this setting, says Gabriel Kreiman, an affiliate of the MIT Center for Brains, Minds, and Machines. Kreinman is a professor of ophthalmology at Boston Children’s Hospital and Harvard Medical School and was lead principal investigator for the study.
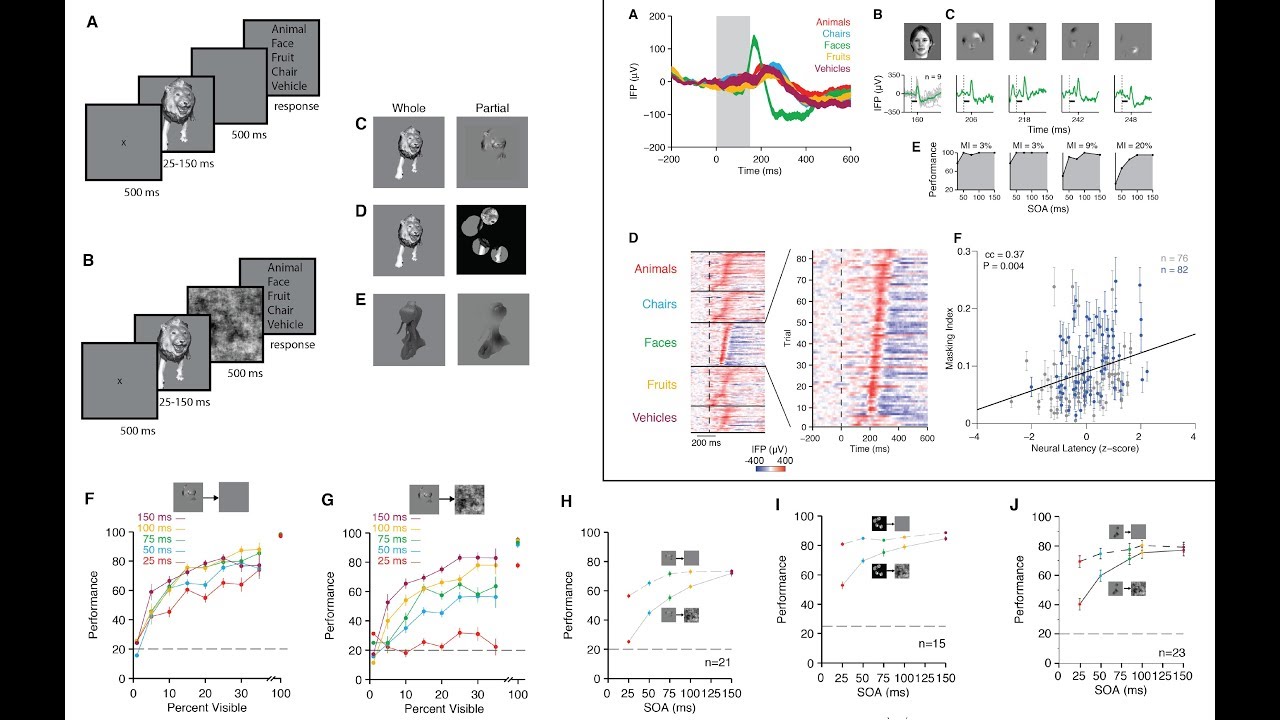
In their paper, "Recurrent computations for visual pattern completion," the team showed how they developed a computational model, inspired by physiological and anatomical constraints, that was able to capture the behavioral and neurophysiological observations during pattern completion. In the end, the model provided useful insights towards understanding how to make inferences from minimal information.
Work for this study was conducted at the Center for Brains, Minds and Machines within the McGovern Institute for Brain Research at MIT.