Wi-Fi is coming to our cars. Ford Motor Co. has been equipping cars with Wi-Fi transmitters since 2010; according to an Agence France-Presse story last year, the company expects that by 2015, 80 percent of the cars it sells in North America will have Wi-Fi built in. The same article cites a host of other manufacturers worldwide that either offer Wi-Fi in some high-end vehicles or belong to standards organizations that are trying to develop recommendations for automotive Wi-Fi.
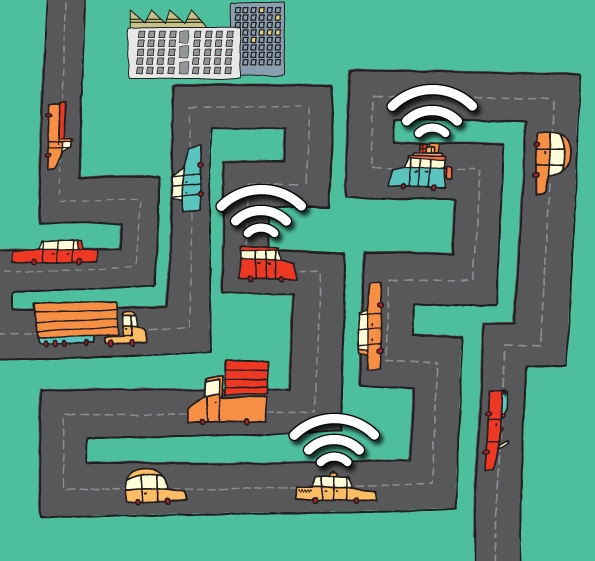
Two Wi-Fi-equipped cars sitting at a stoplight could exchange information free of charge, but if they wanted to send that information to the Internet, they’d probably have to use a paid service such as the cell network or a satellite system. At the ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing, taking place this month in Portugal, researchers from MIT, Georgetown University and the National University of Singapore (NUS) will present a new algorithm that would allow Wi-Fi-connected cars to share their Internet connections. “In this setting, we’re assuming that Wi-Fi is cheap, but 3G is expensive,” says Alejandro Cornejo, a graduate student in electrical engineering and computer science at MIT and lead author on the paper.
The general approach behind the algorithm is to aggregate data from hundreds of cars in just a small handful, which then upload it to the Internet. The problem, of course, is that the layout of a network of cars is constantly changing in unpredictable ways. Ideally, the aggregators would be those cars that come into contact with the largest number of other cars, but they can’t be identified in advance.
Cornejo, Georgetown’s Calvin Newport and NUS’s Seth Gilbert — all three of whom did or are doing their doctoral work in Nancy Lynch’s group at MIT’s Computer Science and Artificial Intelligence Laboratory — began by considering the case in which every car in a fleet of cars will reliably come into contact with some fraction — say, 1/x — of the rest of the fleet in a fixed period of time. In the researchers’ scheme, when two cars draw within range of each other, only one of them conveys data to the other; the selection of transmitter and receiver is random. “We flip a coin for it,” Cornejo says.
Over time, however, “we bias the coin toss,” Cornejo explains. “Cars that have already aggregated a lot will start ‘winning’ more and more, and you get this chain reaction. The more people you meet, the more likely it is that people will feed their data to you.” The shift in probabilities is calculated relative to 1/x — the fraction of the fleet that any one car will meet.
The smaller the value of x, the smaller the number of cars required to aggregate the data from the rest of the fleet. But for realistic assumptions about urban traffic patterns, Cornejo says, 1,000 cars could see their data aggregated by only about five.
Realistically, it’s not a safe assumption that every car will come in contact with a consistent fraction of the others: A given car might end up collecting some other cars’ data and then disappearing into a private garage. But the researchers were able to show that, if the network of cars can be envisioned as a series of dense clusters with only sparse connections between them, the algorithm will still work well.
Weirdly, however, the researchers’ mathematical analysis shows that if the network is a series of dense clusters with slightly more connections between them, aggregation is impossible. “There’s this paradox of connectivity where if you have these isolated clusters, which are well-connected, then we can guarantee that there will be aggregation in the clusters,” Cornejo says. “But if the clusters are well connected, but they’re not isolated, then we can show that it’s impossible to aggregate. It’s not only our algorithm that fails; you can’t do it.”
“In general, the ability to have cheap computers and cheap sensors means that we can generate a huge amount of data about our environment,” says John Heidemann, a research professor at the University of Southern California’s Information Sciences Institute. “Unfortunately, what’s not cheap is communications.”
Heidemann says that the real advantage of aggregation is that it enables the removal of redundancies in data collected by different sources, so that transmitting the data requires less bandwidth. Although Heidemann’s research focuses on sensor networks, he suspects that networks of vehicles could partake of those advantages as well. “If you were trying to analyze vehicle traffic, there’s probably 10,000 cars on the Los Angeles Freeway that know that there’s a traffic jam. You don’t need every one of them to tell you that,” he says.
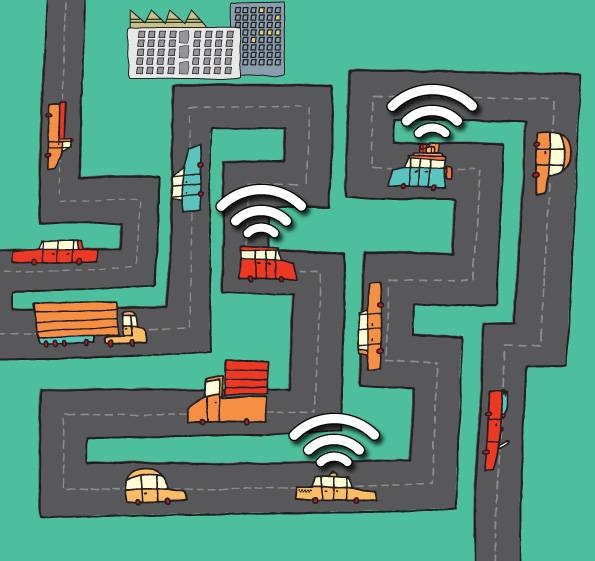
Two Wi-Fi-equipped cars sitting at a stoplight could exchange information free of charge, but if they wanted to send that information to the Internet, they’d probably have to use a paid service such as the cell network or a satellite system. At the ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing, taking place this month in Portugal, researchers from MIT, Georgetown University and the National University of Singapore (NUS) will present a new algorithm that would allow Wi-Fi-connected cars to share their Internet connections. “In this setting, we’re assuming that Wi-Fi is cheap, but 3G is expensive,” says Alejandro Cornejo, a graduate student in electrical engineering and computer science at MIT and lead author on the paper.
The general approach behind the algorithm is to aggregate data from hundreds of cars in just a small handful, which then upload it to the Internet. The problem, of course, is that the layout of a network of cars is constantly changing in unpredictable ways. Ideally, the aggregators would be those cars that come into contact with the largest number of other cars, but they can’t be identified in advance.
Cornejo, Georgetown’s Calvin Newport and NUS’s Seth Gilbert — all three of whom did or are doing their doctoral work in Nancy Lynch’s group at MIT’s Computer Science and Artificial Intelligence Laboratory — began by considering the case in which every car in a fleet of cars will reliably come into contact with some fraction — say, 1/x — of the rest of the fleet in a fixed period of time. In the researchers’ scheme, when two cars draw within range of each other, only one of them conveys data to the other; the selection of transmitter and receiver is random. “We flip a coin for it,” Cornejo says.
Over time, however, “we bias the coin toss,” Cornejo explains. “Cars that have already aggregated a lot will start ‘winning’ more and more, and you get this chain reaction. The more people you meet, the more likely it is that people will feed their data to you.” The shift in probabilities is calculated relative to 1/x — the fraction of the fleet that any one car will meet.
The smaller the value of x, the smaller the number of cars required to aggregate the data from the rest of the fleet. But for realistic assumptions about urban traffic patterns, Cornejo says, 1,000 cars could see their data aggregated by only about five.
Realistically, it’s not a safe assumption that every car will come in contact with a consistent fraction of the others: A given car might end up collecting some other cars’ data and then disappearing into a private garage. But the researchers were able to show that, if the network of cars can be envisioned as a series of dense clusters with only sparse connections between them, the algorithm will still work well.
Weirdly, however, the researchers’ mathematical analysis shows that if the network is a series of dense clusters with slightly more connections between them, aggregation is impossible. “There’s this paradox of connectivity where if you have these isolated clusters, which are well-connected, then we can guarantee that there will be aggregation in the clusters,” Cornejo says. “But if the clusters are well connected, but they’re not isolated, then we can show that it’s impossible to aggregate. It’s not only our algorithm that fails; you can’t do it.”
“In general, the ability to have cheap computers and cheap sensors means that we can generate a huge amount of data about our environment,” says John Heidemann, a research professor at the University of Southern California’s Information Sciences Institute. “Unfortunately, what’s not cheap is communications.”
Heidemann says that the real advantage of aggregation is that it enables the removal of redundancies in data collected by different sources, so that transmitting the data requires less bandwidth. Although Heidemann’s research focuses on sensor networks, he suspects that networks of vehicles could partake of those advantages as well. “If you were trying to analyze vehicle traffic, there’s probably 10,000 cars on the Los Angeles Freeway that know that there’s a traffic jam. You don’t need every one of them to tell you that,” he says.