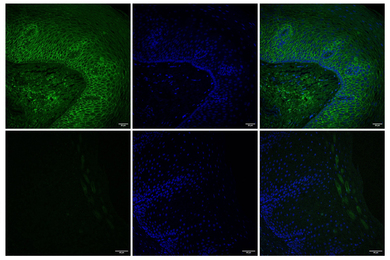
An international team of researchers has discovered the vast majority of the so-called “dark matter” in the human genome, by means of a sweeping comparison of 29 mammalian genomes. The team, led by scientists from the Broad Institute and MIT, has pinpointed the parts of the human genome that control when and where genes are turned on. This map is a critical step in interpreting the thousands of genetic changes that have been linked to human disease. The findings appeared online Oct. 12 in the journal Nature.
Early comparisons of the human and mouse genomes led to the surprising discovery that the regulatory information that controls genes dwarfs the information in the genes themselves. But these studies were indirect: They could infer the existence of these regulatory sequences, but could find only a small fraction of them. These mysterious sequences have been referred to as the “dark matter” of the genome, analogous to the unseen matter and energy that make up most of the universe.
This new study enlisted a menagerie of mammals — including rabbits, bats, elephants and more — to reveal these mysterious genomic elements.
Over the last five years, scientists at the Broad Institute, MIT, Washington University in St. Louis and Baylor College of Medicine have sequenced the genomes of 29 placental mammals. The research team compared all these genomes, 20 of which are first reported in this paper, looking for regions that have remained largely unchanged across species.
“With just a few species, we didn’t have the power to pinpoint individual regions of regulatory control,” says co-author Manolis Kellis, the Karl R. Van Tassel (1925) Career Development Associate Professor of Computer Science at MIT. “This new map reveals almost 3 million previously undetectable elements in non-coding regions that have been carefully preserved across all mammals, and whose disruptions appear to be associated with human disease.”
These findings could yield a deeper understanding of the links between genetic variants and disease.
“Most of the genetic variants associated with common diseases occur in non-protein-coding regions of the genome. In these regions, it is often difficult to find the causal mutation,” says co-author Kerstin Lindblad-Toh, scientific director of vertebrate genome biology at the Broad and a professor in comparative genomics at Uppsala University in Sweden. “This catalog will make it easier to decipher the function of disease-related variation in the human genome.”
A ‘treasure trove’ of genetic information
This new map helps pinpoint mutations that are likely responsible for disease — generally in genes that have been preserved across millions of years of evolution. Knowing the causal mutations and their likely functions can then help uncover the underlying disease mechanisms and reveal potential drug targets.
The scientists were able to suggest possible functions for more than half of the 360 million DNA letters contained in the conserved elements, revealing:
The researchers were also able to harness this collection of genomes to look back in time, across more than 100 million years of evolution, to uncover the fundamental changes that shaped mammalian adaptation to different environments and lifestyles. The researchers revealed specific proteins under rapid evolution, including some related to the immune system, taste perception and cell division. They also uncovered hundreds of protein domains, within genes, that are evolving rapidly, some of which are related to bone remodeling and retinal functions.
“The comparison of mammalian genomes reveals the regulatory controls that are common across all mammals,” says co-author Eric Lander, director of the Broad Institute and professor of biology at MIT. “These evolutionary innovations were devised more than 100 million years ago and are still at work in the human population today.”
Homing in on the human
In addition to finding the DNA controls that are common across all mammals, the comparison highlighted areas that have been changing rapidly only in the human and primate genomes. Researchers had previously uncovered 200 of these regions, some of which are linked to brain and limb development. The expanded list — which now includes more than 1,000 regions — will give scientists new starting points for understanding human evolution.
The comparison of many complete genomes is beginning to offer a clear view of once-indiscernible genomic regions, and with additional genomes, that resolution will only increase. “The power of this resource is that it continues to improve with the inclusion of more species,” Lindblad-Toh says. “It’s a very systematic and unbiased approach that will only become more powerful with the inclusion of additional genomes.”
“This paper represents the culmination of a major effort by three large-scale sequencing centers to annotate the genome using the powerful tools of comparative genomic analysis,” says William Gelbart, a professor of molecular and cellular biology at Harvard University who was not involved in this research. “Taking advantage of the fact that, over geological time frames, evolutionary footprints of many functional sequences in the genome are revealed by showing little if any variation, Lindblad-Toh et al. are able to identify more than a million functional elements in the human genome. Thus, this work is an important step toward the goal of establishing the complete catalog of functional elements in the human genome.”
This project was supported by the National Human Genome Research Institute, the National Institute of General Medical Sciences, the European Science Foundation, the National Science Foundation, the Alfred P. Sloan Foundation, an Erwin Schrödinger Fellowship, the Gates Cambridge Trust, the Novo Nordisk Foundation, the University of Copenhagen, the David and Lucile Packard Foundation, the Danish Council for Independent Research Medical Sciences and the Lundbeck Foundation.
Early comparisons of the human and mouse genomes led to the surprising discovery that the regulatory information that controls genes dwarfs the information in the genes themselves. But these studies were indirect: They could infer the existence of these regulatory sequences, but could find only a small fraction of them. These mysterious sequences have been referred to as the “dark matter” of the genome, analogous to the unseen matter and energy that make up most of the universe.
This new study enlisted a menagerie of mammals — including rabbits, bats, elephants and more — to reveal these mysterious genomic elements.
Over the last five years, scientists at the Broad Institute, MIT, Washington University in St. Louis and Baylor College of Medicine have sequenced the genomes of 29 placental mammals. The research team compared all these genomes, 20 of which are first reported in this paper, looking for regions that have remained largely unchanged across species.
“With just a few species, we didn’t have the power to pinpoint individual regions of regulatory control,” says co-author Manolis Kellis, the Karl R. Van Tassel (1925) Career Development Associate Professor of Computer Science at MIT. “This new map reveals almost 3 million previously undetectable elements in non-coding regions that have been carefully preserved across all mammals, and whose disruptions appear to be associated with human disease.”
These findings could yield a deeper understanding of the links between genetic variants and disease.
“Most of the genetic variants associated with common diseases occur in non-protein-coding regions of the genome. In these regions, it is often difficult to find the causal mutation,” says co-author Kerstin Lindblad-Toh, scientific director of vertebrate genome biology at the Broad and a professor in comparative genomics at Uppsala University in Sweden. “This catalog will make it easier to decipher the function of disease-related variation in the human genome.”
A ‘treasure trove’ of genetic information
This new map helps pinpoint mutations that are likely responsible for disease — generally in genes that have been preserved across millions of years of evolution. Knowing the causal mutations and their likely functions can then help uncover the underlying disease mechanisms and reveal potential drug targets.
The scientists were able to suggest possible functions for more than half of the 360 million DNA letters contained in the conserved elements, revealing:
- almost 4,000 previously undetected exons, or segments of DNA that code for proteins;
- 10,000 highly conserved elements that may be involved in protein production;
- more than 1,000 new families of RNA secondary structures with diverse roles in gene regulation; and
- 2.7 million predicted targets of transcription factors, proteins that control gene expression.
The researchers were also able to harness this collection of genomes to look back in time, across more than 100 million years of evolution, to uncover the fundamental changes that shaped mammalian adaptation to different environments and lifestyles. The researchers revealed specific proteins under rapid evolution, including some related to the immune system, taste perception and cell division. They also uncovered hundreds of protein domains, within genes, that are evolving rapidly, some of which are related to bone remodeling and retinal functions.
“The comparison of mammalian genomes reveals the regulatory controls that are common across all mammals,” says co-author Eric Lander, director of the Broad Institute and professor of biology at MIT. “These evolutionary innovations were devised more than 100 million years ago and are still at work in the human population today.”
Homing in on the human
In addition to finding the DNA controls that are common across all mammals, the comparison highlighted areas that have been changing rapidly only in the human and primate genomes. Researchers had previously uncovered 200 of these regions, some of which are linked to brain and limb development. The expanded list — which now includes more than 1,000 regions — will give scientists new starting points for understanding human evolution.
The comparison of many complete genomes is beginning to offer a clear view of once-indiscernible genomic regions, and with additional genomes, that resolution will only increase. “The power of this resource is that it continues to improve with the inclusion of more species,” Lindblad-Toh says. “It’s a very systematic and unbiased approach that will only become more powerful with the inclusion of additional genomes.”
“This paper represents the culmination of a major effort by three large-scale sequencing centers to annotate the genome using the powerful tools of comparative genomic analysis,” says William Gelbart, a professor of molecular and cellular biology at Harvard University who was not involved in this research. “Taking advantage of the fact that, over geological time frames, evolutionary footprints of many functional sequences in the genome are revealed by showing little if any variation, Lindblad-Toh et al. are able to identify more than a million functional elements in the human genome. Thus, this work is an important step toward the goal of establishing the complete catalog of functional elements in the human genome.”
This project was supported by the National Human Genome Research Institute, the National Institute of General Medical Sciences, the European Science Foundation, the National Science Foundation, the Alfred P. Sloan Foundation, an Erwin Schrödinger Fellowship, the Gates Cambridge Trust, the Novo Nordisk Foundation, the University of Copenhagen, the David and Lucile Packard Foundation, the Danish Council for Independent Research Medical Sciences and the Lundbeck Foundation.